Introduction à la modélisation en épidémiologie : COVID19 - 1er confinement - estimation de la reproductivité du virus
Cécile Berthelot, Alizée Delarue, Aglaé Thieffry, Amélie Picchiottino (M1 Agro Rennes), le 15 mars 2021.
Edité par Frédéric Hamelin et Marine Dorand (M1 MODE), le 28 avril 2021.
Introduction
Nous nous sommes intéressées au cours de ce projet à la modélisation de l'épidémie de Covid-19 lors du premier confinement, à partir du 19 mars (par manque de données les jours précédents).
Pour cela, nous avons récolté des bases de données sur data.gouv.fr. Nous avons utilisé des données portant sur le nombre de tests réalisés en laboratoire de ville, le nombre de tests positifs, le nombre de décès à l'hôpital, le nombre de guérisons après hospitalisation. Nous n’avons pas utilisé de données sur les guérisons et les décès à domicile. Les données sont cumulées à partir du 19 mars.
Sources des données :
https://www.data.gouv.fr/fr/datasets/donnees-hospitalieres-relatives-a-lepidemie-de-covid-19/
Notre étude s’appuie sur les travaux sur le confinement présentés dans cet article :
Modèle épidémiologique
Les variables du modèle sont :
- : le nombre de personnes sensibles au temps ,
- : le nombre de personnes infectées et infectieuses,
- : le nombre de personnes rétablies ou guéries,
- : le nombre de personnes décédées.
La taille de la population est .
Les paramètres du modèles sont
- : le taux de transmission de la maladie,
- : le taux de guérison,
- : le taux de mortalité due à la maladie.
Ce sont des "taux" par unité de temps.

Le modèle s'écrit :
Modèle d'observation
L'ajustement du modèle se fera par maximisation de la vraisemblance (likelihood en anglais). Cette méthode consiste à maximiser la probabilité des observations sachant les paramètres. Le modèle d'observation définit la probabilité qu'un test soit positif au temps d'après le modèle épidémiologique : où est la sensibilité des tests PCR (supposée connue) et est probabilité relative pour les individus sensibles de se faire tester comparativement aux infectés (à estimer). Aussi, le nombre de tests positifs le jour peut être modélisé comme un tirage dans une loi Binomiale de paramètres et (le nombre de tests réalisés le jour ) : le nombre de nouveaux cas observés le jour est Nous faisons l'hypothèse que le nombre de décès cumulés observé au jour est tiré dans une loi de Poisson de moyenne telle que donné par le modèle : En admettant que les observations sont indépendantes conditionnellement au modèle, la vraisemblance s'écrit : Soit le vecteur des paramètres à estimer. Rechercher les valeurs de qui maximisent la vraisemblance est équivalent à rechercher les valeurs de qui maximisent la log-vraisemblance, qui transforme le produit en somme : Nous travaillerons avec la log-vraisemblance.
Traitement des données
Tout d’abord, nous pouvons nettoyer l’environnement de travail en effaçant les anciennes variables :
rm(list=ls()) # Efface les variables créées lors des exécutions précédentes
graphics.off() # Ferme les fenêtres ouvertes lors des exécutions précédentes
Nous importons les librairies nécessaires au projet :
library(deSolve) # pour la fonction ode (ordinary differential equation)
Nous baserons notre travail sur les données hospitalières suivantes :
- donnees-tests-covid19-labo-quotidien-2020-05-29-19h00.csv
- donnees-hospitalieres-nouveaux-covid19-2020-05-10-19h00.csv
Importons les données sous R :
# Lien permanent vers les données de tests
urltest = url("https://www.data.gouv.fr/fr/datasets/r/b4ea7b4b-b7d1-4885-a099-71852291ff20")
# Lien permanent vers les données d'hospitalisations
urlhosp = url("https://www.data.gouv.fr/fr/datasets/r/6fadff46-9efd-4c53-942a-54aca783c30c")
# Tableau lié aux données de tests
datatest = read.csv2(urltest, header=TRUE, sep=";")
# Tableau lié aux données d'hospitalisation
datahosp = read.csv2(urlhosp, header=TRUE, sep=";")
Pour les données liées aux tests, on gardera les données pour toutes les classes d’âges. On conserve seulement les lignes avec clage\_covid=0 :
datatest=datatest[datatest$clage_covid == 0,]
Agrégation des données à l’échelle de la France (tous les départements français) par jour :
# Nombre de tests par jour
nb_test = aggregate(nb_test ~ jour, data = datatest, FUN = sum)
# Nombre de tests positifs par jour
nb_pos = aggregate(nb_pos ~ jour, data = datatest, FUN = sum)
# Nombre de décès par jour
nb_deces = aggregate(incid_dc~ jour, data=datahosp, FUN = sum)
# Nombre quotidien de nouveaux retours à domicile
nb_gueris= aggregate (incid_rad~ jour, data=datahosp, FUN = sum)
Le premier confinement s’est déroulé du 17 mars au 11 mai 2020. Mais les données d’hospitalisations commencent seulement le 19 mars. On sélectionne les données du 19 mars au 11 mai 2020 :
nb_test=nb_test[nb_test$jour>"2020-03-18" & nb_test$jour<"2020-05-12", ]
nb_pos=nb_pos[nb_pos$jour>"2020-03-18" & nb_pos$jour<"2020-05-12", ]
nb_deces = nb_deces[ nb_deces$jour<"2020-05-12", ]
nb_gueris = nb_gueris[ nb_gueris$jour<"2020-05-12", ]
Construction de vecteurs qui contiennent uniquement les données qui nous intéressent :
nb_test=nb_test[,2] # Nombre de tests
nb_pos=nb_pos[,2] # Nombre de tests positifs
nb_deces=nb_deces[,2] # Nombre de décès
nb_gueris=nb_gueris[,2] # Nombre de guéris (nb quotidien de nouveaux retours à domicile)
Construction de vecteurs avec les données cumulées avec la fonction cumsum :
TT=cumsum(nb_test) # Nombre de tests cumulés
PT=cumsum(nb_pos) # Nombre de tests positifs cumulés
DN=cumsum(nb_deces) # Nombre de décès cumulés
GN=cumsum(nb_gueris) # Nombre de guéris cumulés
LP = length(PT)
LT = length(TT)
LD = length(DN)
LG = length(GN)
Construction d’un vecteur du nombre de jours écoulé depuis le 19 mars jusqu’au 11mai :
temps = seq(from=1,to=54, by=1)
Nous avons représenté ci-dessous l’évolution du nombre de tests réalisés (courbe noire) et celle du nombre de tests positifs (courbe bleue) au cours du premier confinement.
plot(temps,TT,xlab="Temps écoulé depuis le 19 mars (en jours)",ylab="Nombre cumulé de tests",pch=16, col="black",main="Evolution des nombres de tests réalisés et de tests positifs
au cours du premier confinement")
points(temps,PT,xlab="Temps écoulé depuis le 19 mars (en jours)",ylab="Nombre de tests positifs",pch=16, col="blue")
legend("topleft",legend=c("Nombre cumulé de tests réalisés","Nombre cumulé de tests positifs"),pch=16,col=c("black","blue"),bty="n")
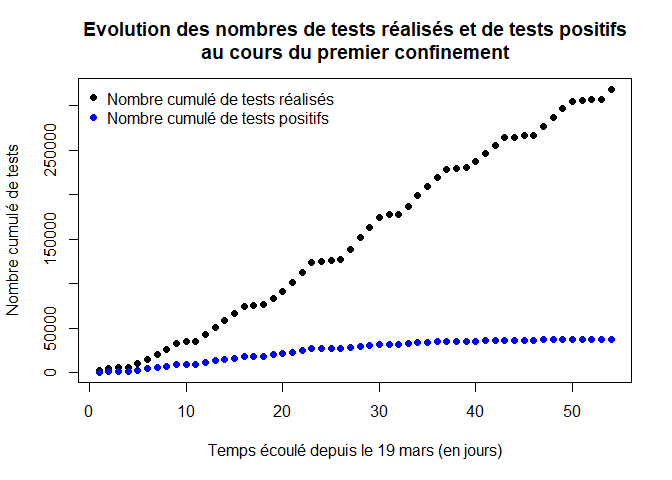
Nous avons représenté ci-dessous l’évolution du nombre de patients guéris (courbe verte) et celle du nombre de décès (courbe rouge) au cours du premier confinement.
plot(temps,GN,xlab="Temps écoulé depuis le 19 mars (en jours)",ylab="Nombre cumulé de cas",pch=16, col="dark green",main="Evolution des nombres de patients testés positifs, guéris ou décédés
au cours du premier confinement")
points(temps,DN,xlab="Temps écoulé depuis le 19 mars (en jours)",ylab="Nombre de décès",pch=16,col="red")
points(temps,PT,xlab="Temps écoulé depuis le 19 mars (en jours)",ylab="Nombre de tests positifs",pch=16, col="blue")
legend("topleft",legend=c("Nombre cumulé de patients guéris","Nombre cumulé de patients décédés","Nombre cumulé de tests positifs"),pch=16,col=c("dark green","red","blue"),bty="n")
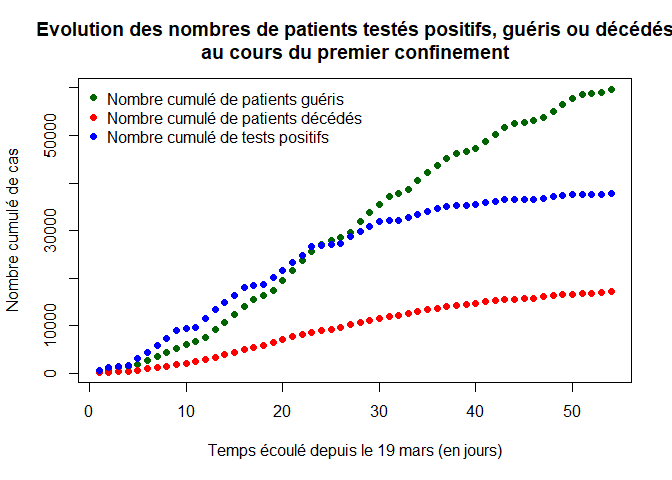
Nous avons représenté ci-dessous la proportion du nombre cumulé de tests positifs sur le nombre cumulé de tests réalisés (courbe bleue) au cours du premier confinement.
PP = PT/TT # proportion de tests positifs
plot(temps,PP,xlab="Temps écoulé depuis le 19 mars (en jours)",ylab="Proportion de tests positifs",pch=16, col="blue", main="Proportion du nombre de tests positifs sur le nombre de tests réalisés au cours du premier confinement")
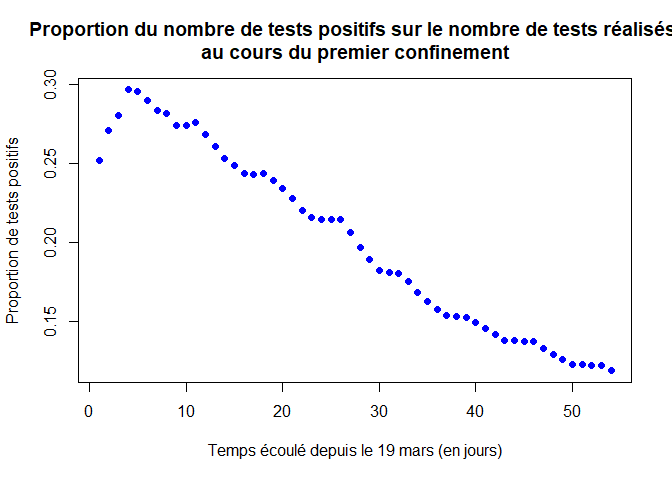
Afin de pouvoir étudier l’évolution du nombre de décès durant le confinement, nous commençons notre étude à la date du 1er avril (13 jours après le 19 mars), car les décès sont retardés d’environ 2 semaines par rapport aux infections.
tau = 13 # Pour commencer le 1er avril
PT = PT[tau:LP]
TT = TT[tau:LT]
DN = DN[tau:LD]
GN = GN[tau:LG]
PP = PP[tau:length(PP)]
Nous nous intéressons maintenant au nombre de tests quotidiens effectués depuis le 1er avril :
pt = nb_pos[tau:LP] # Nombre de tests positifs quotidiens depuis le 1er avril
tt = nb_test[tau:LT] # Nombre de tests quotidiens depuis le 1er avril
dn = nb_deces[tau:LD] # Nombre de décès quotidiens depuis le 1er avril
lt = length(tt)
lp = length(pt)
ld = length(dn)
On redéfini un vecteur temps du nombre de jours écoulé depuis le 1er avril jusqu’au 11 mai :
temps = seq(from=1,to=42, by=1)
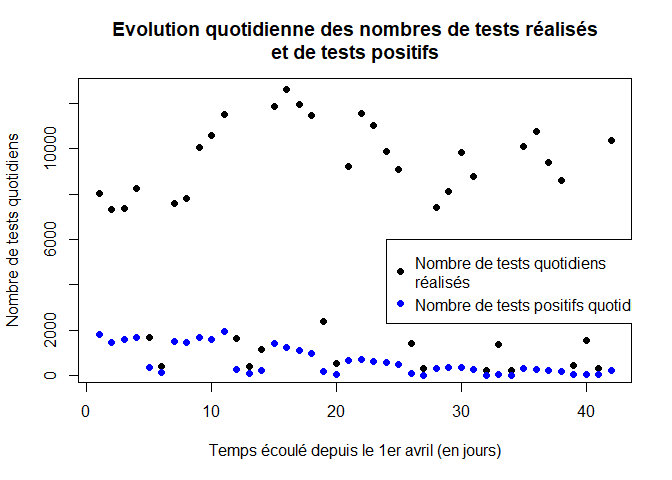
Nous représentons ci-dessous l’évolution quotidienne des nombres de tests réalisés (courbe noire) et de tests positifs (courbe bleue).
plot(temps,tt,xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Nombre de tests quotidiens",pch=16, col="black",main = "Evolution quotidienne des nombres de tests réalisés et de tests positifs")
points(temps,pt,xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Nombre de tests quotidiens positifs",pch=16, col="blue")
legend(x=24, y=6000,legend=c("Nombre de tests quotidiens
réalisés","Nombre de tests positifs quotidiens"),pch=16,col=c("black","blue"))
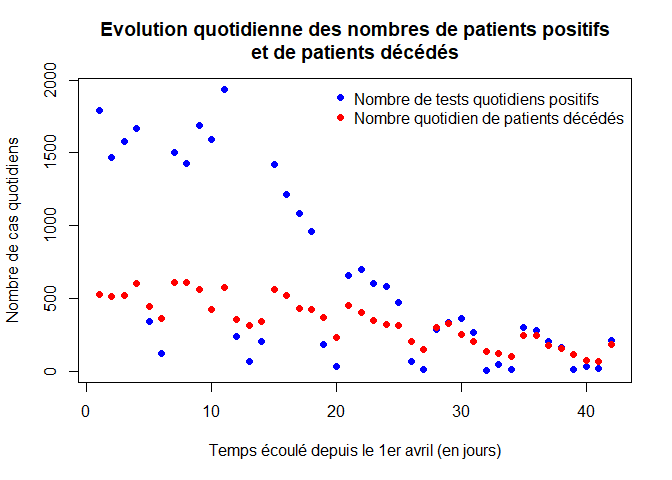
Nous représentons ci-dessous l’évolution quotidienne du nombre de patients positifs (courbe bleue) et de patients décédés (courbe rouge).
plot(temps,pt,xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Nombre de cas quotidiens",pch=16,col="blue",main= "Evolution quotidienne des nombres de patients positifs et de patients décédés")
points(temps,dn,xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Nombre quotidien de décès",pch=16, col="red")
legend("topright",legend=c("Nombre de tests quotidiens positifs","Nombre quotidien de patients décédés"),pch=16,col=c("blue","red"),bty="n")
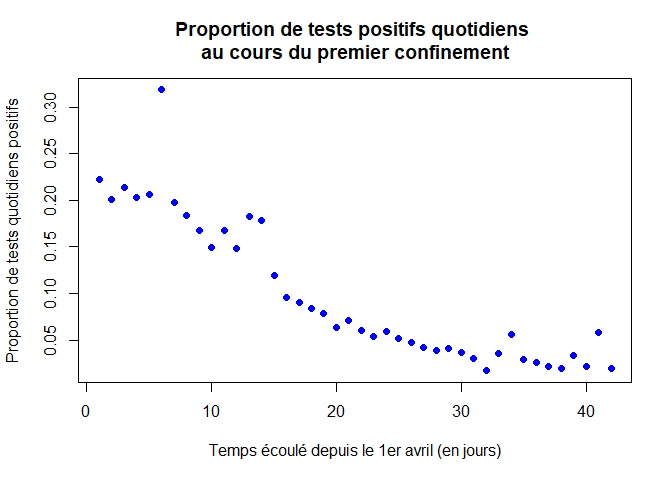
Nous avons représenté ci-dessous la proportion de tests positifs quotidiens sur le nombre de tests réalisés quotidien (courbe bleue) au cours du premier confinement.
pp = pt/tt # proportion de tests positifs quotidiens
plot(temps,pp,xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Proportion de tests quotidiens positifs",pch=16, col="blue",main="Proportion de tests positifs quotidiens au cours du premier confinement")
Ajustement du modèle aux données
Nous définissons les paramètres de notre modèle :
N = 67e6 # Taille totale de la population
gamma = 1/10 # Taux de guérison (par jour)
R_0 = 3 # Reproductivité du virus
beta = gamma*R_0 # R0 = beta/gamma
sigma = 0.7 # Sensibilité des tests PCR
kappa = 5e-3 # Biais d'observation
alpha = 0.01 # Taux de mortalité
t0 = 1 # Correspond au 1er avril, la date du début de l'étude
theta0 = c(beta,kappa,alpha) # Vecteur des paramètres à estimer
Nous définissons les conditions initiales du modèle :
I0 = 1.5e6 # On fixe le nombre initial d'infectés d'après Roques et al 2020
R0 = N*0.01 # Inconnue : on suppose qu'au 1er avril il y avait 1% d'immunisés
D0 = DN[1] # On se sert de la donnée initiale
S0 = N-I0-R0-D0
X0 = c(S0,I0,D0) # Vecteur d'état
Le temps est défini ci-dessous :
t = t0:lt
La fonction du modèle SIRD :
SIRD = function(t, X, P){ # X : vecteur d'état; P : paramètres du modèle
beta = P[1] ; alpha = P[2]
S = X[1] ; I = X[2] ; D = X[3]
y = beta*S*I/N # Nombre de nouvelles infections par jour
dS = -y
dI = +y - gamma*I - alpha*I
dD = +alpha*I
dX = c(dS,dI,dD) # Variations de S, I et D mises à jour
return(list(dX))
}
La fonction qui calcule la vraisemblance des paramètres est définie ci-dessous :
logLike = function(theta){ # theta : vecteur des paramètres à estimer
beta = theta[1]
kappa = theta[2]
alpha = theta[3]
P = c(beta,alpha)
X = ode(X0,t,SIRD,P) # X : vecteur des solutions du modèle SIRD
# Proportion théorique de tests quotidiens positifs d'après le modèle
p1 = sigma*X[,3]/(X[,3]+kappa*X[,2])
# Vraisemblance : calcule la probabilité d'observer pt en connaissant la probabilité théorique p1 qu'un test soit positif (loi binomiale) et d'observer dn en connaissant la quantité théorique quotidienne de décès basée sur le taux de mortalité alpha (loi de poisson)
L = dbinom(pt, tt, p1, log=TRUE) + dpois(dn, alpha*X[,3], log=TRUE)
LL = sum(L)
return(LL)
}
Nous cherchons ensuite à estimer et optimiser le jeu de paramètres de notre modèle à partir des estimations initiales à l’aide d’une fonction optimisant la vraisemblance (logLike) :
opt = optim(theta0,logLike,control=list(fnscale=-1))
beta = opt$par[1] # On extrait les paramètres optimisés par notre modèle
kappa = opt$par[2]
alpha = opt$par[3]
P = c(beta,alpha) # P est le vecteur des paramètres utilisés pour la résolution des équations différentielles
print(paste("beta =",beta,"; alpha =",alpha,"; kappa =",kappa))
Nous trouvons , , et .
Nous utilisons ensuite nos paramètres optimisés pour résoudre notre système d’équations différentielles.
t = t0:42
# X : vecteur des solutions du modèle SIRD avec les paramètres optimisés
X = ode(X0,t,SIRD,P)
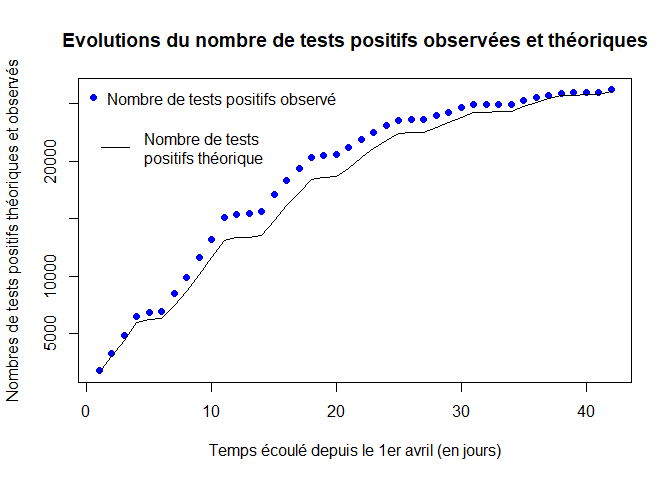
Nous représentons ensuite sur un graphique les évolutions du nombre de tests positifs observées (courbe bleue) et théoriques (courbe noire) calculées à partir du modèle afin de vérifier la qualité de l’ajustement du modèle :
p1 = sigma*X[,3]/(X[,3]+kappa*X[,2]) # Proportion théorique de tests quotidiens positifs
Sigma1 = cumsum(pt[t]) # Somme cumulée du nombre de tests positifs observés
Sigma2 = cumsum(tt[t]*p1) # Proportion de cas positifs cumulée issue du modèle
plot(t, Sigma1, xlab = "Temps écoulé depuis le 1er avril (en jours)", ylab = "Nombres de tests positifs théoriques et observés", main= "Evolutions du nombre de tests positifs observées et théoriques",pch=16, col = "blue")
lines(t,Sigma2)
legend("topleft",legend="Nombre de tests positifs observé",pch=16,col="blue",bty="n")
legend(x=0, y=24000,legend="Nombre de tests
positifs théorique",lty=1,col="black",bty="n")
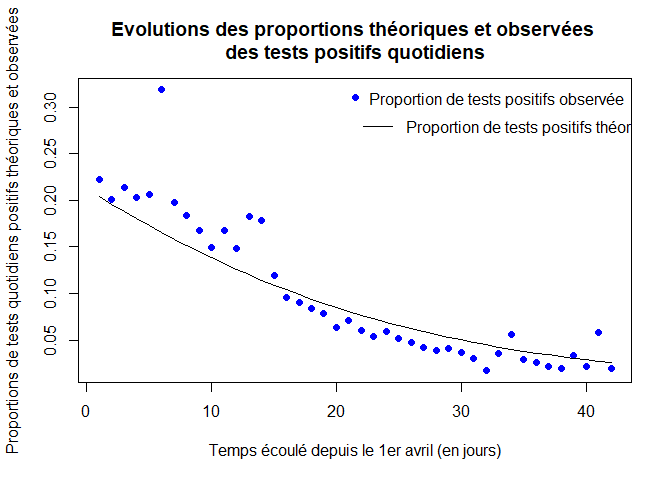
Nous comparons également à l’aide du graphique ci-dessous les évolutions des proportions théoriques (courbe noire) et observées (courbe bleue) des tests positifs quotidiens.
plot(t,pp[t],xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Proportions de tests quotidiens positifs théoriques et observées", main="Evolutions des proportions théoriques et observées
des tests positifs quotidiens",pch=16, col="blue")
lines(t,p1) # p1 : Proportion de tests positifs théoriques
legend("topright",legend="Proportion de tests positifs observée",pch=16,col="blue",bty="n")
legend(x=21, y=0.30,legend="Proportion de tests positifs théorique",lty=1,col="black",bty="n")
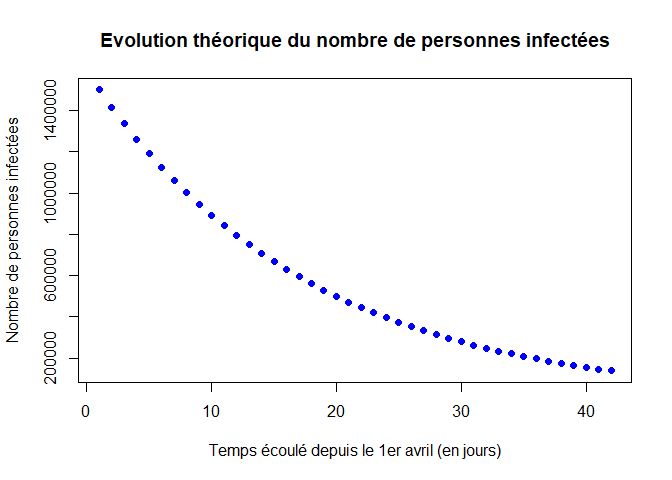
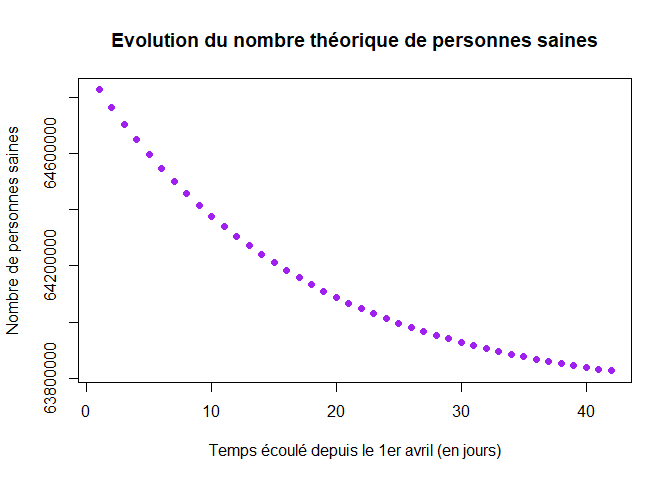
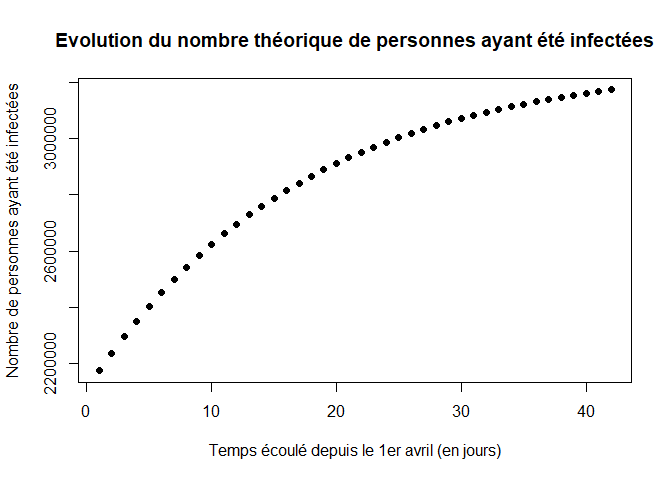
Les graphiques suivant représentent les évolutions théoriques du nombre de personnes infectées au cours du temps, du nombre de personne saines et du nombre de personnes ayant été infectées depuis le début de l’épidémie.
plot(t,X[,3],col="blue",xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Nombre de personnes infectées",pch=16, main="Evolution théorique du nombre de personnes infectées")
plot(t,X[,2],col="purple",xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Nombre de personnes saines",pch=16, main="Evolution du nombre théorique de personnes saines")
plot(t,N-X[,2],xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Nombre de personnes ayant été infectées",pch=16, main="Evolution du nombre théorique de personnes ayant été infectées")
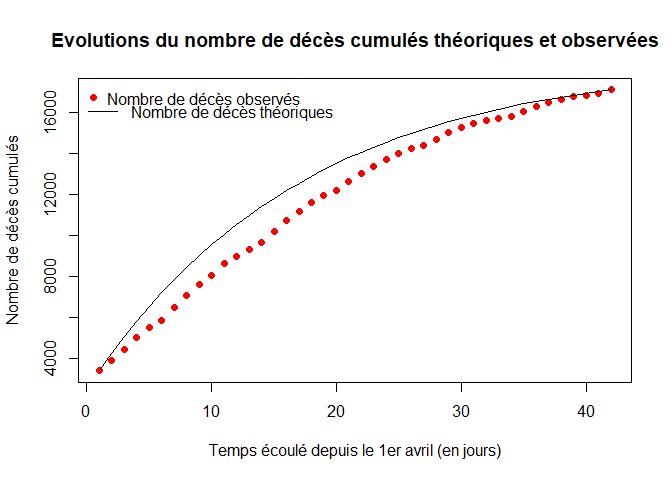
Nous représentons les évolutions du nombre de décès cumulés théoriques (courbe noire) et observées (courbe rouge).
plot(temps,DN,col="red",xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Nombre de décès cumulés",pch=16,main="Evolutions du nombre de décès cumulés théoriques et observées")
lines(t,X[,4])
legend("topleft",legend="Nombre de décès observés",pch=16,col="red",bty="n")
legend(x=-1, y=17000,legend="Nombre de décès théoriques",lty=1,col="black",bty="n")
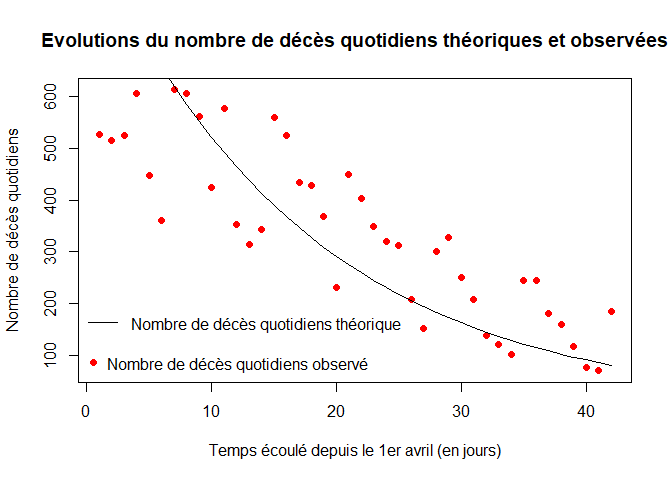
Nous représentons les évolutions du nombre de décès quotidiens théoriques (courbe noire) et observées (courbe rouge).
plot(temps,dn,col="red",xlab="Temps écoulé depuis le 1er avril (en jours)",ylab="Nombre de décès quotidiens",pch=16, main="Evolutions du nombre de décès quotidiens théoriques et observées")
lines(t,alpha*X[,3])
legend("bottomleft",legend="Nombre de décès quotidiens observé",pch=16,col="red",bty="n")
legend(x=-1, y=200,legend="Nombre de décès quotidiens théorique",lty=1,col="black",bty="n")
Estimation de la reproductivité du virus
A l’aide de nos paramètres estimés, nous sommes en mesure de calculer le nombre de reproduction effectif du virus au cours du confinement :
R_e = beta/(gamma+alpha)*(S0/N) # Re : nombre de reproduction effectif du virus
print(paste("R_e=",R_e))
Nous trouvons , ce qui est cohérent avec l'article de Roques et al 2020.
Nous pouvons également estimer le taux de létalité (IFR) du virus durant le 1er confinement :
IFR = alpha/(alpha+gamma) # Infection Fatality Ratio
print(paste("IFR=",IFR))
Nous trouvons un IFR de 0.58%, ce qui est comparable avec la valeur obtenue lors de la première flambée, voir par exemple le précédent article des mêmes auteurs :