Introduction à la modélisation en épidémiologie : COVID-19 - 2ème confinement
Victoria Bancel, Elise Hodbert, Nolwenn Paquet (M1 Agro Rennes), le 11 mars 2021.
Edité par Frédéric Hamelin et Marine Dorand (M1 MODE), le 20 mai 2021.
Dynamique épidémique sur la base des données de tests
Modèle épidémiologique
Dans ce TD, nous allons modéliser la dynamique l'épidémie de COVID19 en France sur la base des données de tests dans un premier temps. Les données concernant les décès seront utilisées dans un second temps pour estimer le taux de létalité de la maladie à la fin de l'année 2020 en France.
Les variables du modèle sont :
- : le nombre de personnes sensibles au temps ,
- : le nombre de personnes infectées et infectieuses,
- : le nombre de personnes rétablies ou guéries,
- : le nombre de personnes décédées.
La taille de la population est .
Les paramètres du modèles sont
- : le taux de transmission de la maladie,
- : le taux de guérison,
- : le taux de mortalité due à la maladie.
Ce sont des "taux" par unité de temps.

Le modèle SIRD s'écrit : Pour simplifier l'étude, nous faisons l'hypothèse que le taux de mortalité due à la maladie est très faible et négligeable d'un point de vue épidémiologique devant le taux de guérison . Cela permet d'approximer la dynamique épidémique de façon indépendante des décès : Le modèle ci-dessus est le célèbre modèle SIR :

Nous ajusterons le modèle SIR aux données de tests. Dans un second temps, nous ajusterons le modèle SIRD aux données de tests et de décès.
Modèle d'observation
L'ajustement du modèle se fera par maximisation de la vraisemblance. Cette méthode consiste à maximiser la probabilité des observations sachant les paramètres. Le modèle d'observation définit la probabilité qu'un test soit positif au temps d'après le modèle épidémiologique : où est la sensibilité des tests PCR (supposée connue) et est probabilité relative pour les individus sensibles de se faire tester comparativement aux infectés (à estimer). Aussi, le nombre de tests positifs le jour peut être modélisé comme un tirage dans une loi Binomiale de paramètres et (le nombre de tests réalisés le jour ) : le nombre de nouveaux cas observés le jour est Nous faisons l'hypothèse que le nombre de décès cumulés observé au jour est tiré dans une loi de Poisson de moyenne telle que donné par le modèle : En admettant que les observations sont indépendantes conditionnellement au modèle, la vraisemblance (likelihood en anglais) s'écrit : Soit le vecteur des paramètres à estimer. Rechercher les valeurs de qui maximisent la vraisemblance est équivalent à rechercher les valeurs de qui maximisent la log-vraisemblance, qui transforme le produit en somme : Nous travaillerons avec la log-vraisemblance.
Traitement des données
Importation du package nécessaire au programme :
# Importe la fonction ode qui permet de résoudre une équation différentielle
library(deSolve)
library(dplyr)
Mise au propre de l’espace de travail :
rm(list=ls()) # Efface les variables créées lors des exécutions précédentes
graphics.off() # Ferme les fenêtres ouvertes lors des exécutions précédentes
Importation du jeu de données sur les tests :
# Lien permanent vers les données de tests
urltest = url("https://www.data.gouv.fr/fr/datasets/r/dd0de5d9-b5a5-4503-930a-7b08dc0adc7c")
#Tableau lié aux données de tests
data1 = read.csv2(urltest, header=TRUE, sep=";")
#On selectionne les colonnes jour, Tests positifs, tests, et classe d'age
data<-data1 %>%
select(jour,P,T,cl_age90) %>%
filter(cl_age90=="0") %>% #Pour les données liées aux tests, on gardera les données pour toutes les classes d'âges. On conserve seulement les lignes avec clage_covid=0
filter(jour>= "2020-10-30",jour<= "2020-12-15" ) #sélection des dates du 2ème confinement
Construction des vecteurs des données cumulées :
pt=as.integer(as.character(data[,2])) # Vecteur concernant les tests positifs quotidiens
tt=as.integer(as.character(data[,3])) # Vecteur concernant les tests réalisés quotidiens
PT = cumsum(pt) # Tests positifs cumulés
TT = cumsum (tt) # Tests réalisés cumulés
Définition de la longueur de notre série de données, c’est-à-dire du nombre de jours d’épidémie étudiés :
LP = length(PT); LT = length(TT); lt = length(tt); lp = length(pt)
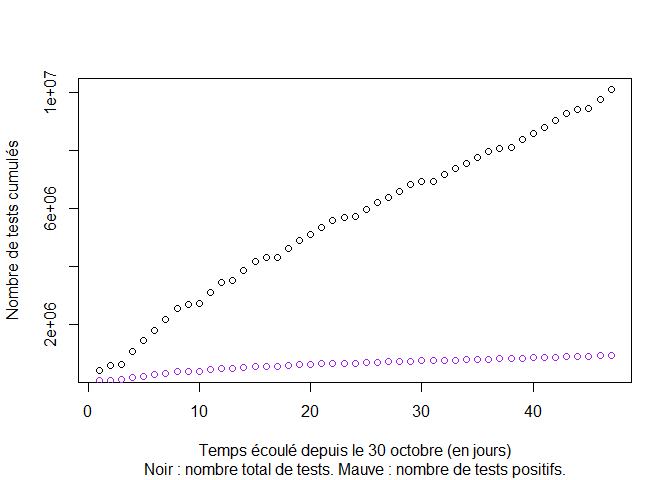
Visualisation des données cumulées à partir du 30 octobre 2020 :
plot(1:LT,TT,xlab="Temps écoulé depuis le 30 octobre (en jours)",ylab="Nombre de tests cumulés",col="black", sub = "Noir : nombre total de tests. Mauve : nombre de tests positifs.")
points(1:LP,PT,col="purple")
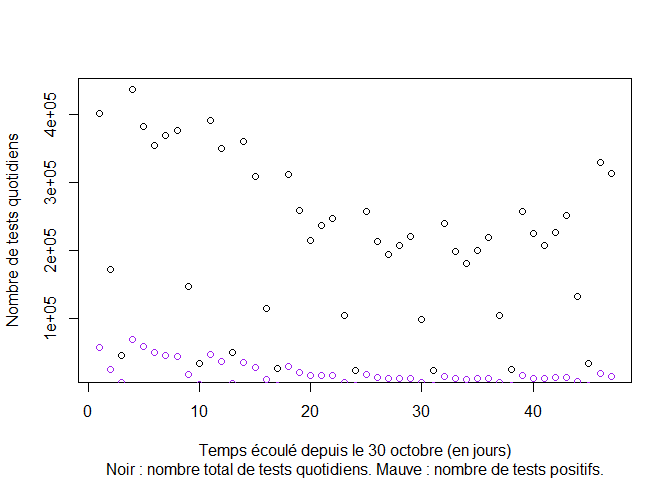
Visualisation des données journalières à partir du 30 octobre 2020 :
plot(1:lt,tt,xlab="Temps écoulé depuis le 30 octobre (en jours)",ylab="Nombre de tests quotidiens",col="black", sub = "Noir : nombre total de tests quotidiens. Mauve : nombre de tests positifs.")
points(1:lp,pt,col="purple")
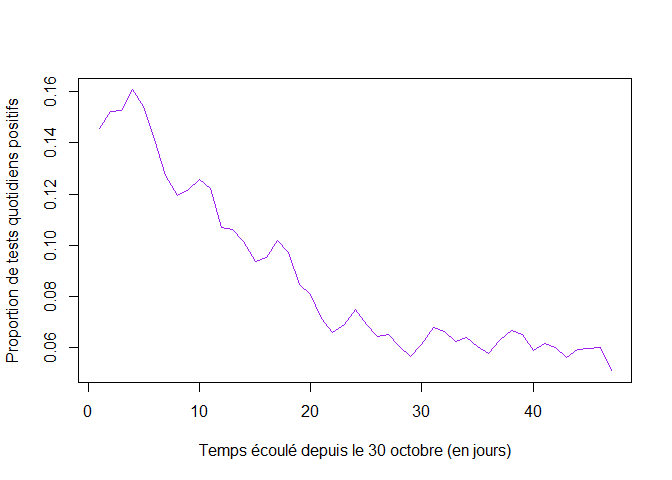
Proportion de tests positifs :
pp = pt/tt # Proportion de tests positifs journaliers
plot(1:lp,pp,xlab="Temps écoulé depuis le 30 octobre (en jours)",ylab="Proportion de tests quotidiens positifs",col="purple", type = "l")
Ajustement du modèle aux données
Initialisation des paramètres du modèle :
N = 64e6 # Taille totale de la population
gamma = 1/10 # Taux de guérison par jour, correspond à l'inverse de la période infectieuse (alpha = 1/ periode infectieuse = 1 / 10)
R_0 = 1 # Reproductivité du virus
beta = gamma*R_0 # R0 = beta/alpha (nombre d'infections secondaires suite à l'introduction d'un individu infecté au sein d'une population naïve)
sigma = 0.7 # Sensibilité des tests PCR
kappa = 5e-3 # Biais d'observation
Conditions initiales (en ) :
t0 = 1 # Début du modèle qui correspond au début du second confinement
P0 = c(beta,kappa) # Vecteur des paramètres à estimer
I0 = 1e6 # Nombre d'infectés au 30 octobre (estimation grossière basée sur le fait qu'environ 300000 personnes ont été testées positives du 23 au 30 octobre)
R0 = (10/100)*N # Nombre de personnes immunisées au 30 octobre (estimation grossière)
S0 = N-I0-R0 # Nombre de personnes sensibles au COVID-19, c'est-à-dire qui n'ont pas encore été contaminées
X0 = c(S0,I0) # Vecteur d'état, on ne prend que S et I car on peut retrouver facilement R avec ces deux valeurs (R=N-S-I)
Modèle SIR :
t=t0:lt # Vecteur temps
SIR = function(t, X, P){
beta = P[1]
S = X[1]
I = X[2]
y = beta*S*I/N # Nombre de nouvelles infections par jour
dS = -y
dI = +y - gamma*I
dX=c(dS,dI)
return(list(dX))
}
Fonction qui calcule la vraisemblance des paramètres :
logLike=function(theta){
P=theta[1:2]
beta=P[1]
kappa=P[2]
X=ode(X0,t,SIR,beta)
p=sigma*X[,3]/(X[,3]+kappa*X[,2]) # Proportion théorique de tests quotidiens positifs
L=dbinom(pt, tt, p, log=TRUE) # Probabilité d'observer "pt" positifs sachant le nombre de tests "tt" et "p(t)" telle que donnée par le modèle (loi binomiale)
LL=sum(L) # Log transforme produit des probas en somme
return(LL)
}
Estimation des paramètres :
theta0 = P0 # estimation initiale
opt=optim(theta0,logLike,control=list(fnscale=-1))
beta=opt$par[1]
kappa=opt$par[2]
t=t0:lt
X=ode(X0,t,SIR,beta)
p=sigma*X[,3]/(X[,3]+kappa*X[,2])# Proportion théorique de tests quotidiens positifs
plot(t,p,xlab="Temps écoulé depuis le 30 octobre (en jours)",ylab="Proportion théorique de tests quotidiens positifs",type="l",col="blue")
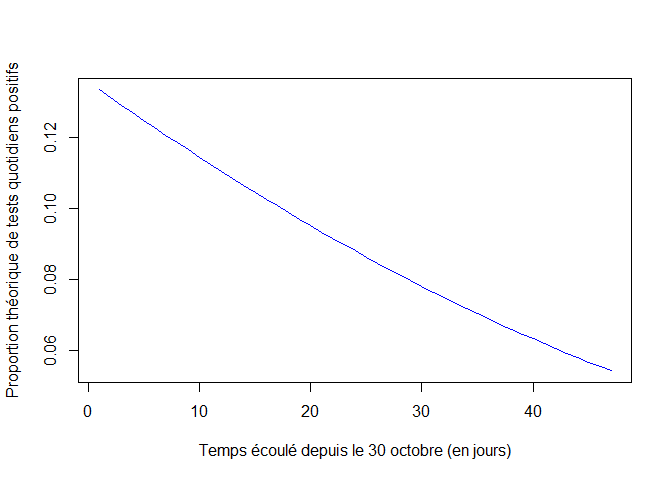
Nombres de tests quotidiens positifs observé et théorique :
Sigma1=(pt[t]) # Nombre de tests quotidiens positifs observé
Sigma2=(tt[t]*p) # Nombre de tests quotidiens positifs théorique
Graphiques des résultats :
plot(t,Sigma1,xlab="Temps écoulé depuis le 30 octobre (en jours)",ylab="Nombre de tests positifs théoriques et observés",col="black")
lines(t,Sigma2)
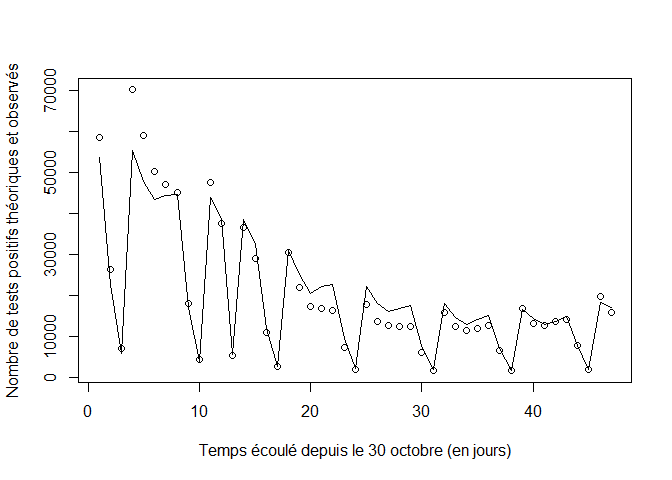
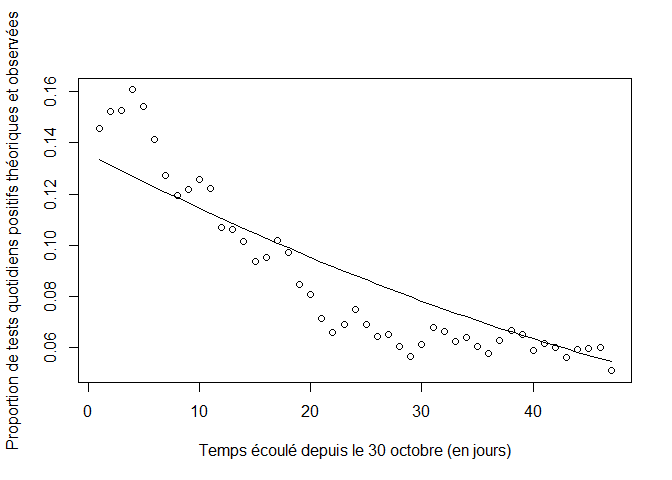
plot(t,pp[t],xlab="Temps écoulé depuis le 30 octobre (en jours)",ylab="Proportion de tests quotidiens positifs théoriques et observées")
lines(t,p)
Estimation de la reproductivité du virus
Paramètres obtenus :
R_0 = beta/(gamma)*(S0/N)
print(R_0)
On obtient une reproductivité associée au deuxième confinement.
Pour aller plus loin : prise en compte des décès
Cette extension a été réalisée par Marine Dorand dans le cadre d'un stage de M1 MODE en avril-mai 2021.
Traitement des données
On importe les données de décès liés aux hospitalisations les données utilisées qui viennent de data.gouv.fr : donnees-hospitalieres-nouveaux-covid19-2021-05-12-19h05.csv
# Lien permanent vers les données d'hospitalisations
urlhosp = url("https://www.data.gouv.fr/fr/datasets/r/6fadff46-9efd-4c53-942a-54aca783c30c")
# Tableau lié aux données d'hospitalisations
datahosp = read.csv2(urlhosp, header=TRUE, sep=";")
Agrégation des données à l’échelle de la France (tous les départements français) par jour :
# Nombre de décès par jour
nb_deces = aggregate(incid_dc~ jour, data=datahosp, FUN = sum)
On séléctionne les données du 30 octobre au 15 décembre 2020 :
nb_deces <-filter(nb_deces, jour>= "2020-10-30",jour<= "2020-12-15" )
Construction du vecteur qui contient uniquement les données de décès :
dc = nb_deces[,2] # Nombre de décès
dccum = cumsum(dc) - dc[1] # Nombre de décès cumulés depuis le 30 octobre
LD = length(dc)
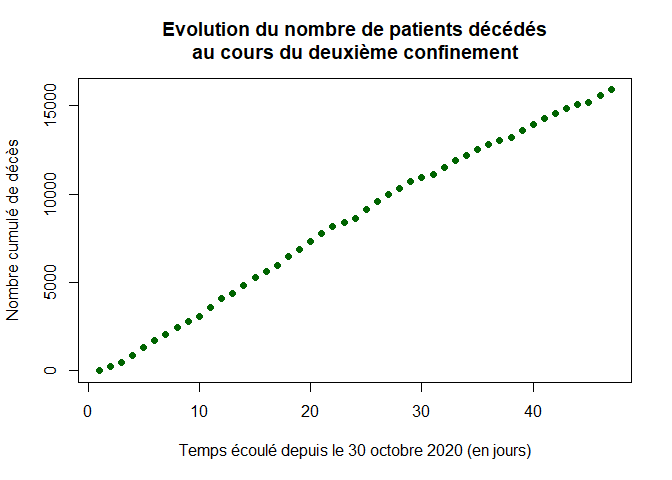
On représente l’évolution du nombre cumulé de patients décédés dans les hôpitaux depuis le 30 octobre :
plot(1:LD,dccum,xlab="Temps écoulé depuis le 30 octobre 2020 (en jours)",ylab="Nombre cumulé de décès",pch=16, col="dark green",main="Evolution du nombre de patients décédés
au cours du deuxième confinement")
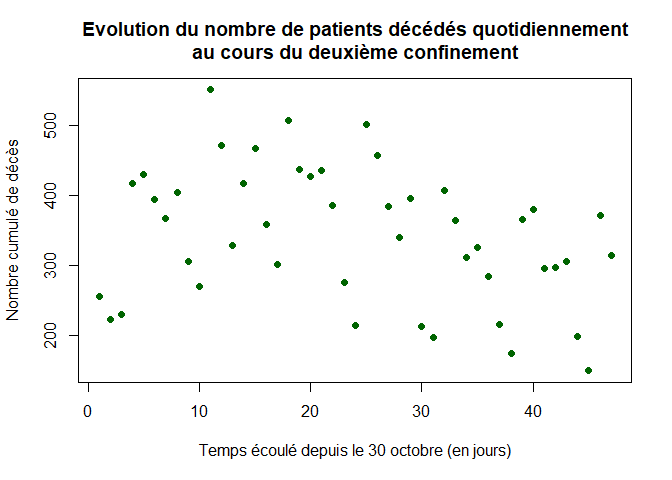
On represente l’évolution du nombre quotidien de patients décédés dans les hopitaux au cours du deuxième confinement :
plot(1:LD,dc,xlab="Temps écoulé depuis le 30 octobre (en jours)",ylab="Nombre cumulé de décès",pch=16, col="dark green",main="Evolution du nombre de patients décédés quotidiennement
au cours de la deuxième flambée")
Ajustement du modèle aux données
On définit les paramètres du modèle SIRD
N = 67e6 # Taille de la population française
gamma = 1/10 # Taux de guérison (inverse du temps moyen avant guérison)
R_0 = 1 # Reproductivité du virus
beta=gamma*R_0 # Taux de transmission du virus
sigma = 0.7 # Sensibilité des tests
kappa = 5e-3 # Biais d'observation
alpha = 0.01 # Taux de mortalité additionnel dû à l'infection
theta0 = c(beta,kappa,alpha) # Vecteur des paramètres à estimer
On définit les conditions initiales :
t0 = 1 # Le 30 octobre
t = t0:LD # vecteur temps
I0 = 1e6 # On suppose qu'au 30 octobre il y a 1e6 infectieux (estimation grossière)
R0 = 10/100*N # On suppose qu'au 30 octobre il y a 10% d'immunisés (estimation grossière)
D0 = dccum[t0] # Nombre de décès au 30 octobre 2020
S0 = N-I0-R0-D0 # Nombre de personnes susceptibles d'êtres infectées
X0 = c(S0,I0,D0) # Vecteur d'état (conditions initiales)
La fonction du modèle SIRD :
SIRD = function(t, X, P){
beta = P[1] ; alpha = P[2]
S = X[1] ; I = X[2] ; D = X[3]
y = beta*S*I/N # Nouvelles infections par unité de temps
dS = -y
dI = +y - gamma*I - alpha*I
dD = +alpha*I
dX = c(dS,dI,dD)
return(list(dX))
}
La fonction qui calcule la vraisemblance des paramètres :
logLike = function(theta){
beta = theta[1]
kappa = theta[2]
alpha = theta[3]
P = c(beta,alpha)
X = ode(X0,t,SIRD,P)
# Proportion théorique de tests quotidiens positifs d'après le modèle
p = sigma*X[,3]/(X[,3]+kappa*X[,2])
dcth = alpha*X[,3] # Décès théoriques
LLT = dbinom(pt[t], tt[t], p, log=TRUE) # Proba d'observer "pt" test positifs au tps t
LLD = dpois(dc[t], dcth, log=TRUE) # Probabilité d'observer "dc" décès au temps t
LL = sum(c(LLT,LLD))
return(LL)
}
On optimise la fonction LogLike pour trouver les paramètres et conditions initiales qui maximisent la vraisemblance du modèle :
opt = optim(theta0,logLike,control=list(fnscale=-1))
On rècupère les paramètres et conditions initiales optimaux :
beta = opt$par[1]
kappa = opt$par[2]
alpha = opt$par[3]
P0 = c(beta,alpha) # Vecteur des paramètres mis à jour
On calcule la solution du modèle pour les paramètres et les conditions initiales estimés :
X = ode(X0,t,SIRD,P0)
p=sigma*X[,3]/(X[,3]+kappa*X[,2])
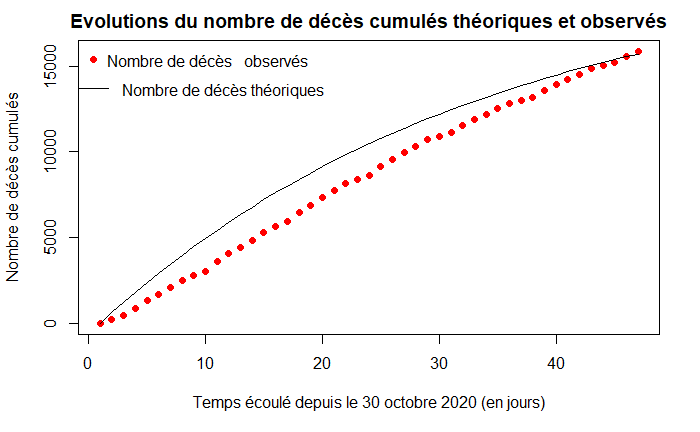
On représente les évolutions des nombres cumulés de décès théoriques (courbe noire) et observés (courbe rouge) :
plot(1:LD,dccum,col="red",xlab="Temps écoulé depuis le 30 octobre 2020 (en jours)",ylab="Nombre de décès cumulés",pch=16,main="Evolutions du nombre de décès cumulés théoriques et observés")
lines(t,X[,4])
legend("topleft",legend="Nombre de décès observés",pch=16,col="red",bty="n")
legend(x=-2, y=14800,legend="Nombre de décès théoriques",lty=1,col="black",bty="n")
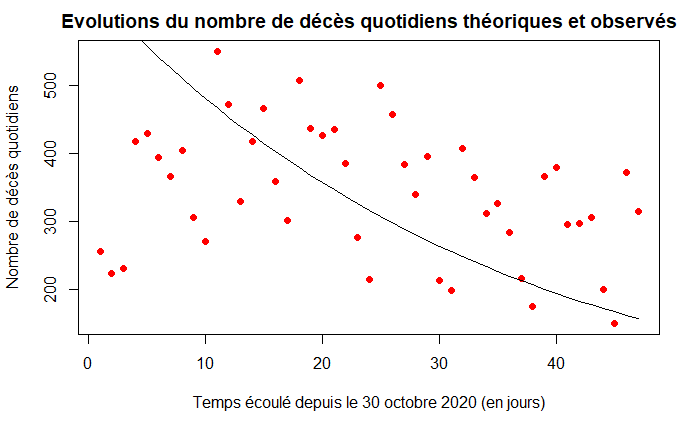
On représente l'évolution du nombre de décès quotidiens théoriques (courbe noire) et observés (courbe rouge) :
plot(1:LD,dc,col="red",xlab="Temps écoulé depuis le 30 octobre 2020 (en jours)",ylab="Nombre de décès quotidiens",pch=16, main="Evolutions du nombre de décès quotidiens théoriques et observés")
lines(t,alpha*X[,3])
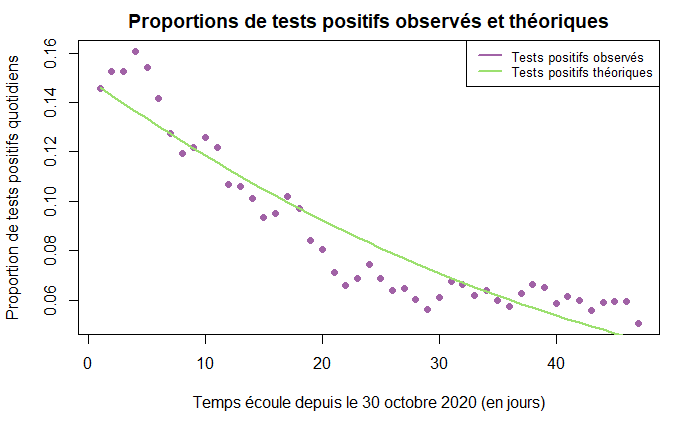
On réalise de nouveau un graphe représentant l’évolution de la proportion de tests positifs observés, PP, et de la proportion théorique de tests positifs calculés, p, après ajustement du modèle SIRD.
pp=pt/tt
plot(t,pp[t],pch=16,col="#A162A6",
xlab="Temps écoule depuis le 30 octobre 2020 (en jours)",
ylab="Proportion de tests positifs quotidiens",
main = "Proportions de tests positifs observés et théoriques")
lines(t,p, lwd=2, col="#9CE06F")
legend("topright", legend=c("Tests positifs observés", "Tests positifs théoriques"),col=c("#A162A6", "#9CE06F"), lty=1, cex = 0.8,lwd=2)
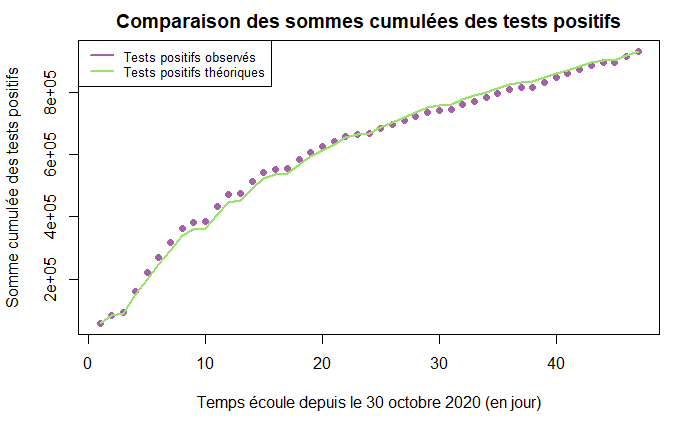
Puis, on compare (somme cumulée des tests positifs observés) avec (somme cumulée des tests positifs observés) obtenues avec le nouveau modèle SIRD. On fait ensuite un graphique des sommes cumulées des tests positifs théoriques du modèle SIRD et observés.
sigma1=cumsum(pt[t])
#nombre total de tests réalisés * proportion de tests positifs théoriques
sigma2=cumsum(tt[t]*p)
plot(t,sigma1,pch=16,xlab="Temps écoule depuis le 30 octobre 2020 (en jour)",ylab="Somme cumulée des tests positifs",col="#A162A6", main = "Comparaison des sommes cumulées des tests positifs")
lines(t,sigma2,lwd=2, col = "#9CE06F" )
legend("topleft", legend=c("Tests positifs observés", "Tests positifs théoriques"),
col=c("#A162A6", "#9CE06F"), lty=1, cex = 0.8, lwd=2)
Estimation de la reproductivité du virus
A l’aide de nos paramètres estimés, nous sommes en mesure de calculer le nombre de reproduction effectif du virus au cours de la deuxième flambée :
R_e2 = beta/(gamma+alpha)*(S0/N) # Re : nombre de reproduction effectif du virus
print(paste("R_e=",R_e2))
On trouve une reproductivité de .
Nous pouvons également estimer le taux de létalité (IFR) du virus durant le deuxième confinement :
IFR = alpha/(alpha+gamma) # Infection Fatality Ratio
print(paste("IFR=",IFR))
Nous trouvons un IFR de 0.8%.
Dynamique épidémique sur la base des données d'hospitalisations
Modèle épidémiologique
Nous définissons les variables
- : nombre d'individus sensibles au virus (non-infectés) à la date ,
- : nombre d'individus infectés et infectieux non-hospitalisés à la date ,
- : nombre d'individus infectés hospitalisés à la date ,
- : nombre d'individus "retirés" de l'épidémie (guéris et immunisés ou décédés) à la date ,
et les paramètres
- : taux de transmission par unité de temps (fréquence des contacts probabilité d'infection),
- : taux de "guérison" par unité de temps (inverse du temps moyen avant guérison ou décès),
- : taux d'hospitalisation par unité de temps (inverse du temps moyen avant hospitalisation),
- : taux de guérison ou décès à l'hôpital (inverse du temps moyen avant sortie de l'hôpital).

Le modèle SIHR se traduit mathématiquement par le système d'équations différentielles :
La taille de la population est définie comme La reproductivité du pathogène est défini comme C'est le nombre d'infections secondaires générées par un individu infecté dans la population initiale :
- si une vague épidémique se forme.
- si l'épidémie s'éteint progressivement.
La probabilité d'être hospitalisé suite à l'infection est Nous allons maintenant tenter d'ajuster ce modèle aux données de COVID-19 en France sous R. Ces données concernent le nombre de personnes hospitalisées à la date , , ainsi que le nombre d'admissions à l'hôpital à la date (par unité de temps) :
Modèle d'observation
Nous considérerons que le nombre de nouvelles hospitalisations à la date est une variable aléatoire discrète distribuée selon une loi de Poisson de moyenne . De la même façon, nous considérerons que le nombre de personnes hospitalisées à la date est tiré dans une loi de Poisson de moyenne .
Appelons le vecteur des paramètres et conditions initiales à estimer : Sous l'hypothèse que les observations sont indépendantes conditionnellement au modèle épidémiologique (ce qui veut dire "sachant la dynamique prédite par le modèle théorique"), la vraisemblance (likelihood) peut s'écrire : Comme la fonction logarithme est monotone croissante, trouver le vecteur qui maximise est équivalent à trouver le vecteur qui maximise la log-vraisemblance (log-likelihood) qui est plus communément utilisée en pratique. Nous travaillerons avec la log-vraisemblance.
Traitement des données
Importation du package nécessaire au programme :
# Importe la fonction ode qui permet de résoudre une équation différentielle
library(deSolve)
Mise au propre de l’espace de travail :
rm(list=ls()) # Efface les variables créées lors des exécutions précédentes
graphics.off() # Ferme les fenêtres ouvertes lors des exécutions précédentes
Importation du jeu de données sur les hospitalisations :
# Lien permanent vers les données d'hospitalisations
urlhosp = url("https://www.data.gouv.fr/fr/datasets/r/d3a98a30-893f-47f7-96c5-2f4bcaaa0d71")
# Tableau lié aux données d'hospitalisation
data = read.csv2(urlhosp, header=TRUE, sep=",")
Création d’un tableau avec seulement les données du 2ème confinement :
j2confifi = which(data[]=="2020-10-30") # Jour à partir duquel commence 2ème confinement
dernierjconfifi = which(data[]=="2020-12-15") # Dernier jour du 2ème confinement
newtableau = data[j2confifi:dernierjconfifi,] # Tableau avec que données 2ème confinement
Vecteurs des données d’hospitalisations et d’admissions à l’hôpital pendant le 2ème confinement :
# Personnes admises à l'hopital depuis le début du deuxième confinement
A = c(newtableau[,10])
H = c(newtableau[,8]) # Personnes hospitalisées depuis le début du deuxième confinement
Visualisation des données d’hospitalisations et d’admissions à l’hôpital pendant le 2ème confinement :
nj = length(newtableau[,1])
plot(1:nj, A,xlab="Temps écoulé depuis le 30 octobre 2020 (en jours)", ylab="Nombre d'admissions à l'hopital", col="blue")
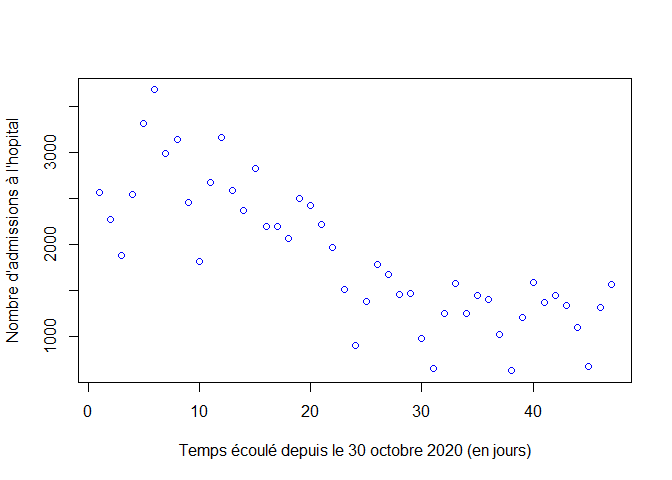
plot(1:nj, H,xlab="Temps écoulé depuis le 30 octobre 2020 (en jours)", ylab="Nombre de personnes hospitalisées",col="blue")
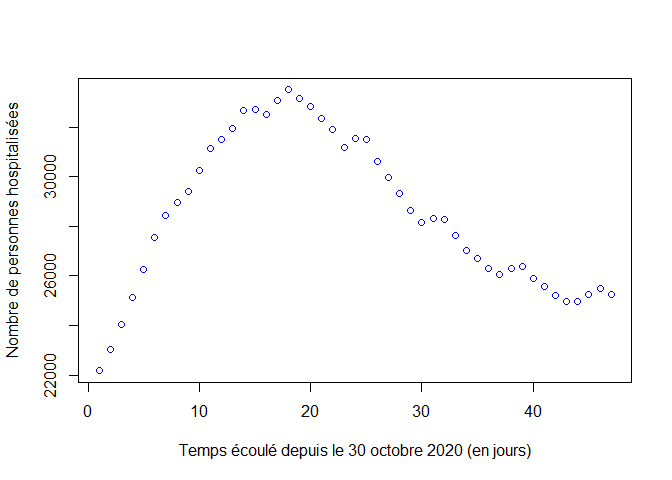
Ajustement du modèle aux données
Initialisation du modèle (le 30 octobre 2020) :
N = 64e6 # Taille de la population
rho = 1/10 # Temps moyen avant guérison ou décès : 10 jours
gamma = 1/14 # Durée moyenne de l'hospitalisation : 14 jours
R_0 = 1 # Nombre de reproduction de base en confinement
beta = R_0*rho # Approximation du taux de transmission
p = 0.1 # Probabilité d'être hospitalisé suite à l'infection
alpha = p*rho/(1-p) # Taux d'hospitalisation
P0 = c(beta,alpha,gamma) # Vecteur des paramètres
H0 = H[1] # Le nombre de personnes hospitalisées au 30 octobre 2020
I0 = A[1]/alpha # Les admissions correspondent à A(t) = alpha*I(t)
R0 = (10/100)*N # Nombre de personnes immunisées au 30 octobre (estimation grossière)
S0 = N-I0-R0 # Nombre de personnes susceptibles d'être infectées
S0 = N-I0-H0-R0 # La taille de la population sensible au 30 octobre
X0 = c(S0,I0,H0) # Vecteur d'état. Pas besoin de simuler R=N-(S+I+H).
Modèle SIHR :
t=0:nj
SIHR = function(t, X, P){
beta = P[1] # Le taux de transmission
alpha = P[2] # Le taux d'hospitalisation
gamma = P[3] # Le taux de sortie d'hôpital
S = X[1]
I = X[2]
H = X[3] # Le vecteur d'état X contient: S, I, et H
y = beta*S*I/N # Le nombre de nouvelles infections par jour
dS = -y # On exprime dS/dt = - beta*S*I
dI = y-(alpha+rho)*I # On exprime dI/dt = beta*S*I - (alpha+rho)*I
dH = alpha*I -gamma*H # On exprime dH/dt = alpha*I - gamma*H
dX=c(dS,dI,dH) # Renvoie dX/dt tel que demandé par la fonction ode
return(list(dX))
}
Fonction de log-vraisemblance :
logLike=function(theta){
P = theta[1:3] # Les paramètres beta, alpha, et gamma
X0 = theta[4:6] # Mise à jour des conditions initiales
X = ode(X0,t,SIHR,P) # Résolution du système d'EDO (modèle SIHR)
h = X[,4] # Hospitalisation théoriques : H(t)
a = P[2]*X[,3] # Admissions théoriques : alpha*I(t)
LLH = dpois(H,h,log=T) # Probabilité d'observer H (loi de Poisson)
LLA = dpois(A,a,log=T) # Probabilité d'observer A (Poisson)
LL = sum(c(LLH,LLA)) # Log transforme produit des probas en somme
return(LL) # Renvoie la log-vraisemblance (likelihood)
}
Arguments d'entrée de la fonction de log-vraisemblance :
theta0 = c(P0,X0) # Concatène les paramètres et conditions initiales
Maximisation de la log-vraisemblance :
opt = optim(theta0,logLike,control=list(fnscale=-1)) # Maximise logLike
Récupération des valeurs optimales des paramètres et conditions initiales du modèle :
#Les paramètres optimaux
beta = opt$par[1]
alpha = opt$par[2]
gamma = opt$par[3]
#Les conditions initiales optimales
S0 = opt$par[4]
I0 = opt$par[5]
H0 = opt$par[6]
Mise à jour des vecteurs des conditions initiales :
X0 = c(S0,I0,H0) # Vecteur des conditions initiales
P0 = c(beta,alpha,gamma) # Vecteur des paramètres mis à jour
Simulation du modèle pour les conditions initiales et paramètres estimés :
T = nj ; t0 = 1 ; t = t0:T # Mise à jour du vecteur temps
X = ode(X0,t,SIHR,P0) # Calcul de la solution optimale
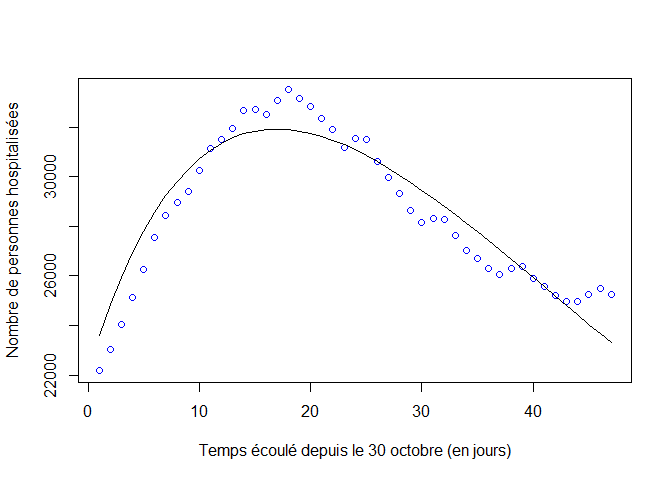
Comparaison visuelle de la solution du modèle et des observations :
# Affiche le nombre d’individus hospitalisés (données et modèle)
plot(1:nj,H,xlab="Temps écoulé depuis le 30 octobre (en jours)",
ylab="Nombre de personnes hospitalisées",col="blue")
lines(X[,1],X[,4])
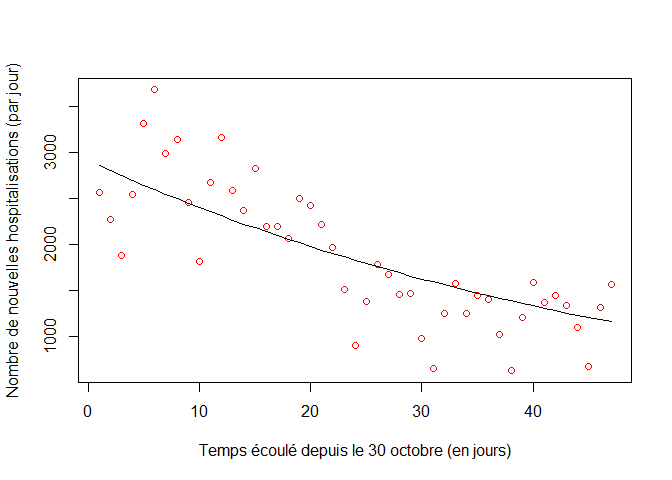
plot(1:nj,A,xlab="Temps écoulé depuis le 30 octobre (en jours)",
ylab="Nombre de nouvelles hospitalisations (par jour)",col="red");
lines(X[,1],alpha*X[,3])
Estimation de la reproductivité du virus
Affichage des valeurs estimées des paramètres :
R_0=beta/(alpha+rho)*S0/N # Nombre de reproduction de base estimé
print(R_0)
p=alpha/(alpha+rho) # Probabilité d'être hospitalisé
print(p)
print(1/gamma) # Temps moyen d'hospitalisation
Nous obtenons les estimations suivantes pour le deuxième confinement :
- Reproductivité du virus : ,
- Probabilité d'être hospitalisé : ,
- Temps moyen d'hospitalisation : jours.